当前位置 鱼摆摆网 > 教程 > 电商培训 >
淘宝成立于哪一年哪一天(讲解淘宝优惠最大的节日)
公众号:阿里云数据库 作者:阿里云数据库 2021-05-22 14:09面对性能和成本的双重压力,阿里数据库内核团队如何应对?
01
淘宝交易订单系统介绍
天猫和淘宝每天发生的实物和虚拟商品的交易达到亿级别。一次成功交易的整个链路会涉及到会员信息验证,商品库信息查询,订单创建,库存扣减,优惠扣减,订单支付,物流信息更新,确认支付等。
链路中的每一环都涉及到数据库中记录的创建和状态的更新,一次成功的交易可能对应到后台信息系统上数百次数据库事务操作,支撑交易系统的整个数据库集群则会承担每日高达数百亿的事务读写。这除了给数据库系统带来巨大的性能挑战之外,每日递增的海量数据也带来巨大的存储成本压力。
交易订单作为其中最为关键的信息,由于可能涉及交易纠纷处理,需要随时提供用户查询,必须永久的记录在数据库中。淘宝成立至今近17年,所有与订单相关的数据库记录总量达到了万亿级别,其所占用的磁盘空间也早已超过PB级。
在一个这样大体量的数据集上,需要能够满足用户随时查询的低延时需求,同时需要达到极低的存储成本,在技术上是一个非常大的挑战。
用户的历史订单记录数据量巨大且不能丢失
02
淘宝交易订单库的架构演进历史
淘宝从2003年成立至今近17年的时间,随着流量不断上涨,交易订单数据库的架构也经历过数次演进。
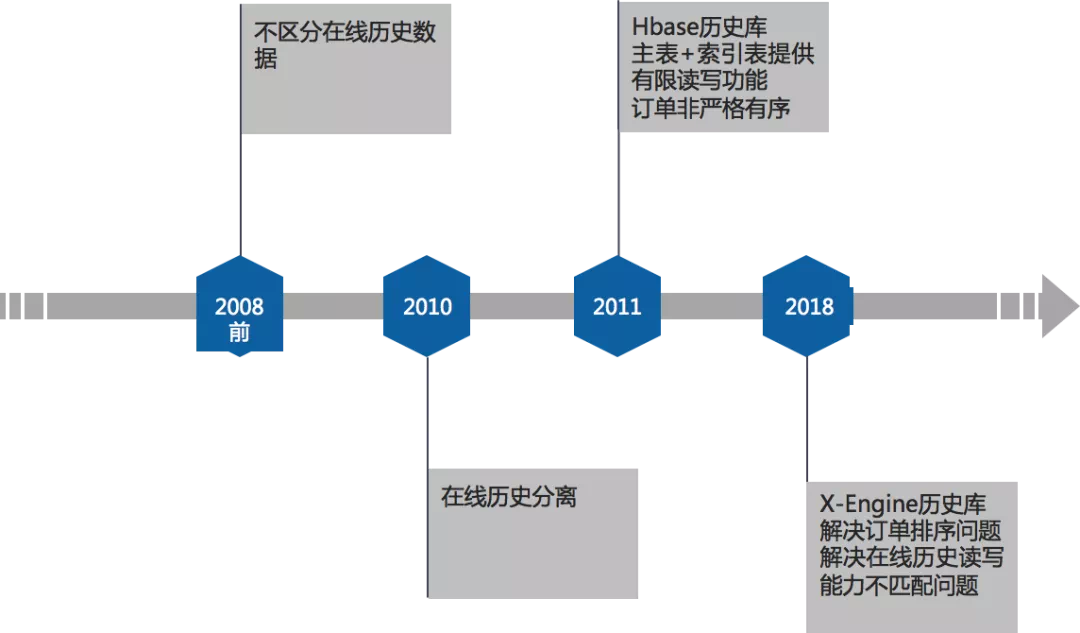
第一阶段,开始由于流量较小,使用了一套Oracle数据存储了所有的订单信息,新订单创建和历史订单查询都在同一套数据库进行。
第二阶段,由于历史订单量数据量越来越大,单一一套库已经不能满足同时满足性能和容量的问题,于是对交易订单库进行了拆分,单独建立了一个Oracle历史库,将三个月以前的订单迁移进历史库,同时由于数据量巨大,查询性能不能满足需求,因此当时的历史订单不提供查询功能。用户只能查询三个月之内的订单信息。
第三个阶段,为了解决扩展性和存储成本问题,交易历史库整体迁移到了HBase方案,这套方案在当时很好了解决了存储成本和业务查询需求这2个诉求。整体方案是使用主表结合索引表,查询订单详细信息通过主表完成,通过买家或者卖家ID查询订单,则需要借助索引表先得到订单号。
但这个方案遗留一个问题:订单并不是严格按照90天进行迁移的,有很多类型的订单并不迁移到历史库,导致已买到--订单列表的排序是乱序的,已买到的订单列表不是严格按照时间由近到远排序的,用户如果按照订单列表一页一页往下翻,会发现自己最近的订单”突然丢了”(实际上没有丢的,只是乱序了,再往后翻就有了)。
第四个阶段,历史库采用基于X-Engine引擎的PolarDB-X集群,在满足存储成本的同事,提供与在线库一样的索引能力,解决乱序问题。
03
淘宝交易订单库的业务痛点
回顾淘宝交易库的演进历史,自拆分出独立的交易历史库之后,在持续十年时间里,业务团队和数据库团队一直在应对几个核心的挑战:
存储成本,每日写入量巨大且数据永不删除,必须要保证极低的成本。
节省存储成本的前提下,保证丰富的查询特性,例如按时间维度排序等。因此底层数据库需要支持二级索引,且二级索引需要保证一致性和性能。
保证较低的查询延时,不影响用户使用体验。虽然90天前的历史订单的查询量比90天内要少很多,但这依然是直接面对用户的,需要保证长尾延时在一定限度内。
在2018年,因为数据库存储的原因导致的订单排序错乱的问题,受到越来越多的投诉,给用户带来非常大的困扰,业务上决定根治这个问题。从前面的分析总结看,理想中的交易历史库方案需要同时满足三个条件: 低成本,低延时,特性丰富。使用和在线库一样的InnoDB引擎则满足不了存储成本的要求,而使用HBase则满足不了一致性二级索引等要求。
04
基于X-Engine引擎的历史库方案
2018年,阿里自研的X-Engine引擎逐步在集团内部落地,其针对阿里巴巴交易业务的流水型特征设计了原生的冷热分离的架构,X-Engine引擎中的冷数据记录在数据页中紧凑排列并默认对所有数据块进行压缩,这套架构兼顾了性能和成本,很快在内部非常多的业务中落地,例如:X-Engine如何支撑钉钉数据量激增。
在考察交易历史库的方案时,一个思路是合并在线库和历史库,依赖X-Engine自身的冷热分离能力, 实现对90天内交易订单的高性能访问和90天以前交易订单记录的低成本存储。同时一套统一的交易订单库,可以提供诸如二级索引等功能,用户订单不能按时间排序的问题也随之解决,业务层的代码将非常简单。
但交易订单系统在在线库/历史库分离的架构下迭代了十年的时间,很多业务系统的代码对这套分离架构做了兼容,考虑到对业务代码改造以及迁移的风险,我们在初期继承了之前在线和历史分离的架构。只是将原有的HBase集群替换成了PolarDB-X集群(基于X-Engine引擎的版本):
在线库依然沿用之前的MySQL InnoDB集群,但是只保存90天的数据量,90天之前的订单会被删除,数据量少,可以保证较高的缓存命中率,确保读写延时。
通过数据同步将在线库中超过90天的订单迁移到历史库中,迁移之后该部分订单从在线库删除。
历史库切换为X-Engine,保存全量的交易订单数据,90之前的订单读写,直接操作历史库, 同时历史库承接在线库的所有迁移写入负载。
(点击查看大图)
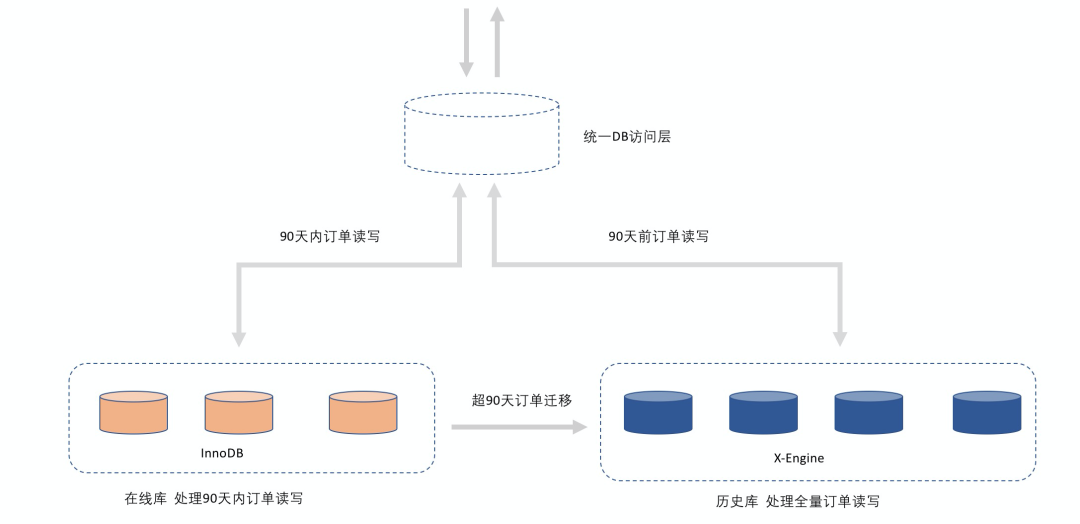
这套架构上线之后,交易历史库的存储成本相比较于使用HBase没有上升,同时由于历史库和在线库能力相同,可以创建完全一样的索引,历史订单恢复了对订单按时间排序功能的支持,同时其读取延时也得到了保证。
05
数据库架构参考
在淘宝交易历史库的方案中,考虑到业务层面历史代码架构的延续性,采用了InnoDB引擎在线库和X-Engine历史库分离的方案。在这套架构中,X-Engine历史库其实同时承担了在线库迁移过来的写入以及90天以前记录的读写流量。
实际上,考虑到淘宝交易订单记录流水型的访问特征(最近写入的记录会被大量访问,随着时间推移,记录访问频次急剧衰减),X-Engine引擎内部的冷热分离机制就能很好的处理这种流水型业务,所以单一X-Engine数据库集群完全解决需求。
对于新开业务或者有大量流水型记录存储需求的现有业务且业务层面还未做冷热分离,我们建议直接使用一套X-Engine引擎,在存储成本降低的同时,DB层的访问代码会更简单。基于X-Engine引擎的PolarDB-X分布式数据库可以同时解决scale out问题和成本问题。
目前X-Engine引擎已经上线阿里云, 经过阿里内部业务验证,欢迎有成本和性能需求的用户购买使用。



- 全部评论(0)

